Case Study
1. Introduction
Bubble is an open-source solution that automates the deployment of preview apps for dynamic frontend applications.
Whenever a developer makes a pull request for a new UI/UX feature they are working on, Bubble will automatically build and deploy a fully-functioning draft of their web application—called a preview app—and provide a shareable URL. This makes it easy for all relevant stakeholders to immediately review the changes and give feedback.
Bubble integrates with GitHub repositories and automates the deployment and teardown of preview apps through a developer’s own AWS account, allowing developers to maintain full control over their source code and self-hosted cloud-based infrastructure. All preview apps can be easily managed through Bubble’s CLI tool as well as its user-friendly dashboard interface.
This case study delves into the problems faced by developers that Bubble aims to solve, how Bubble works, and the key design decisions and tradeoffs we made when building it.
2. Brief History of Web Development
To understand Bubble’s use case, we’ll need to be familiar with the web development architecture a typical Bubble user’s application would be built with. Let’s take a step back and walk through a brief history of how web development approaches have evolved.
2.1 Server-Side Rendering

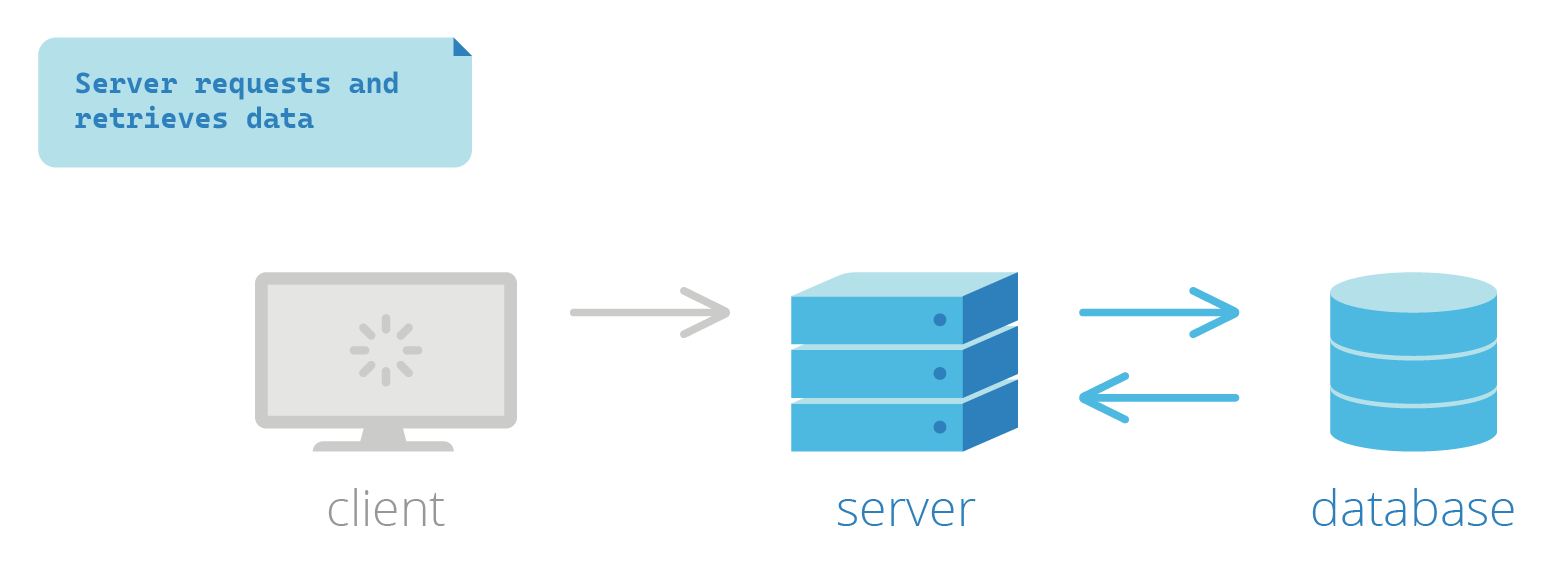

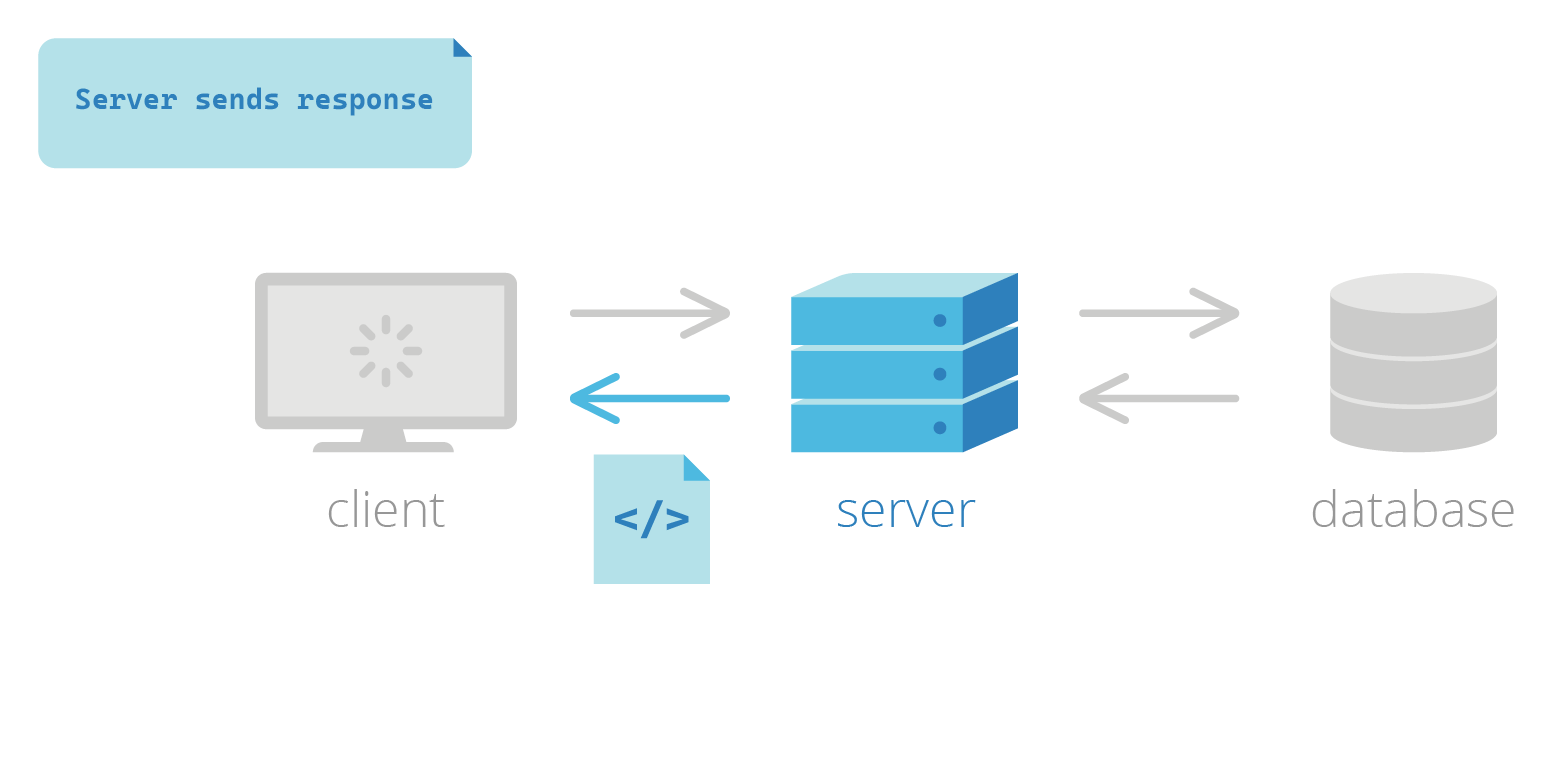

Traditionally, the most common strategy for building web pages was based on client-server communication: a client—for example, an end user’s browser—would request a page from a website and the server would be responsible for responding with a fully-generated HTML page.1 With this approach, the server does most of the heavy lifting at request time. When it receives the request, the server fetches any data from the database along with other resources (i.e., CSS, images, etc.) needed, generates the full HTML, and then sends it back to the client to display to the end user. This process, appropriately named server-side rendering (SSR), is repeated with every request from the client.
2.2 Static Site Generation

As websites grew to serve more and more content, it became clear that some of this content didn’t necessarily need to be completely “dynamic,” meaning there would be little to no change required for a given page’s content on every request. For example, consider a company’s landing page or a blog post, where the content of these pages remains the same for long periods of time regardless of who’s requesting it—it quickly becomes wasteful and inefficient for the server to dynamically regenerate these kinds of pages each time a client makes a request. This led to the rise in popularity of static site generation (SSG).2
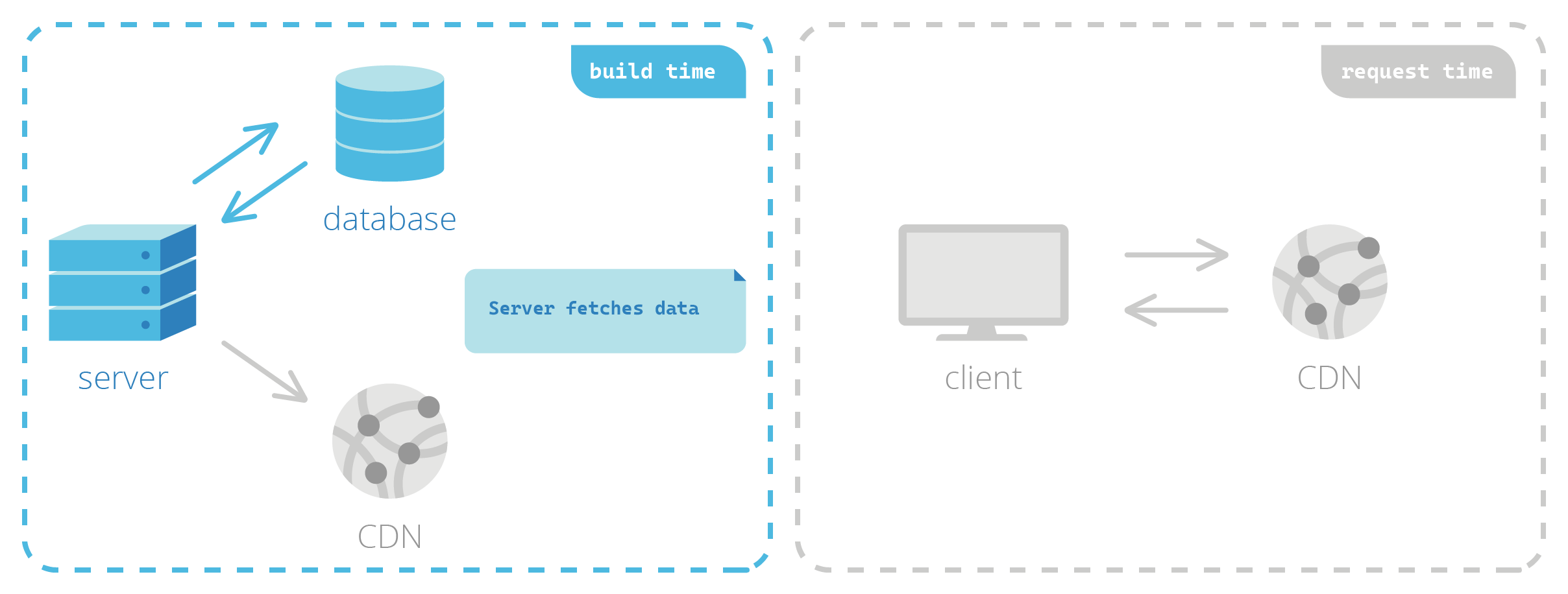

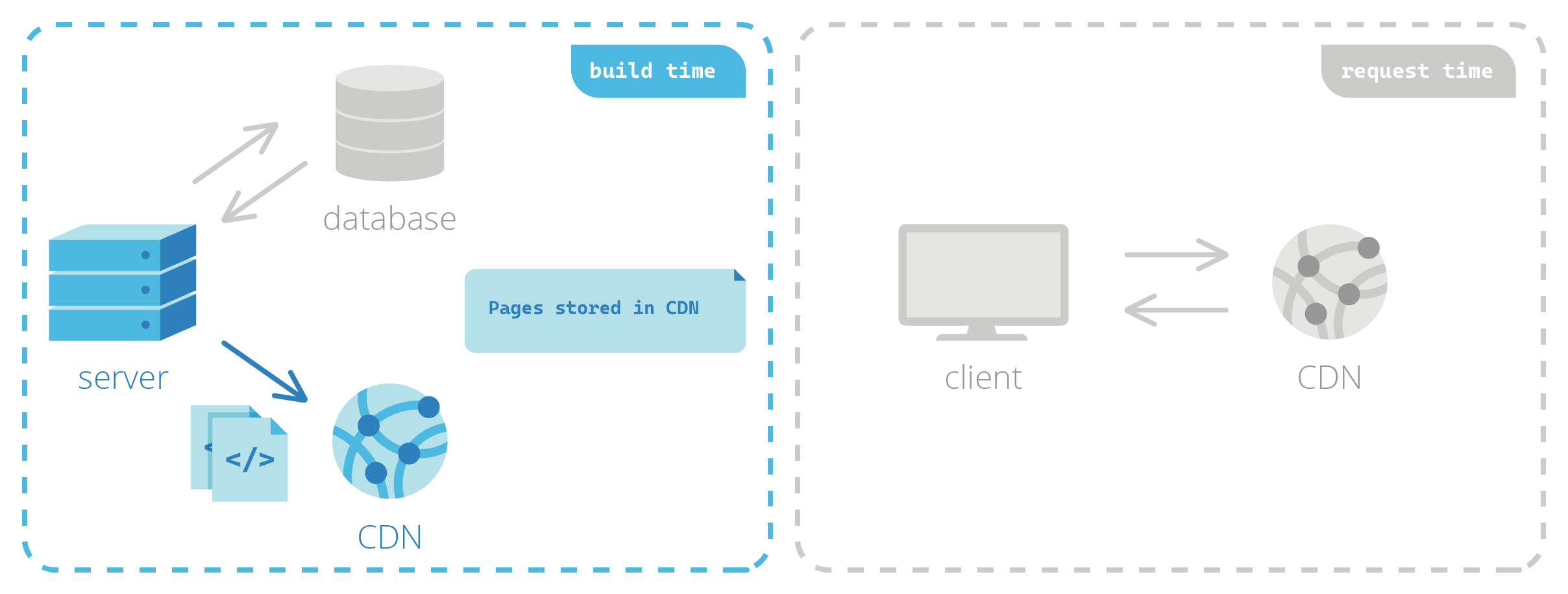

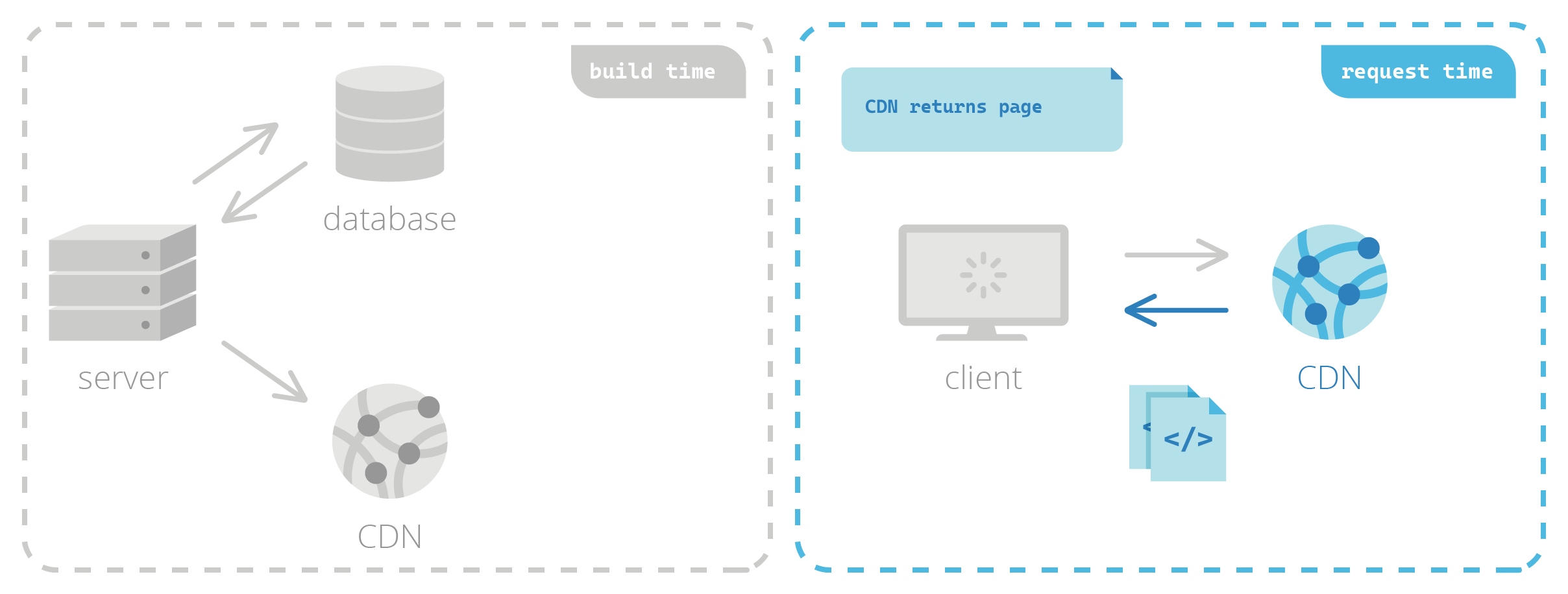
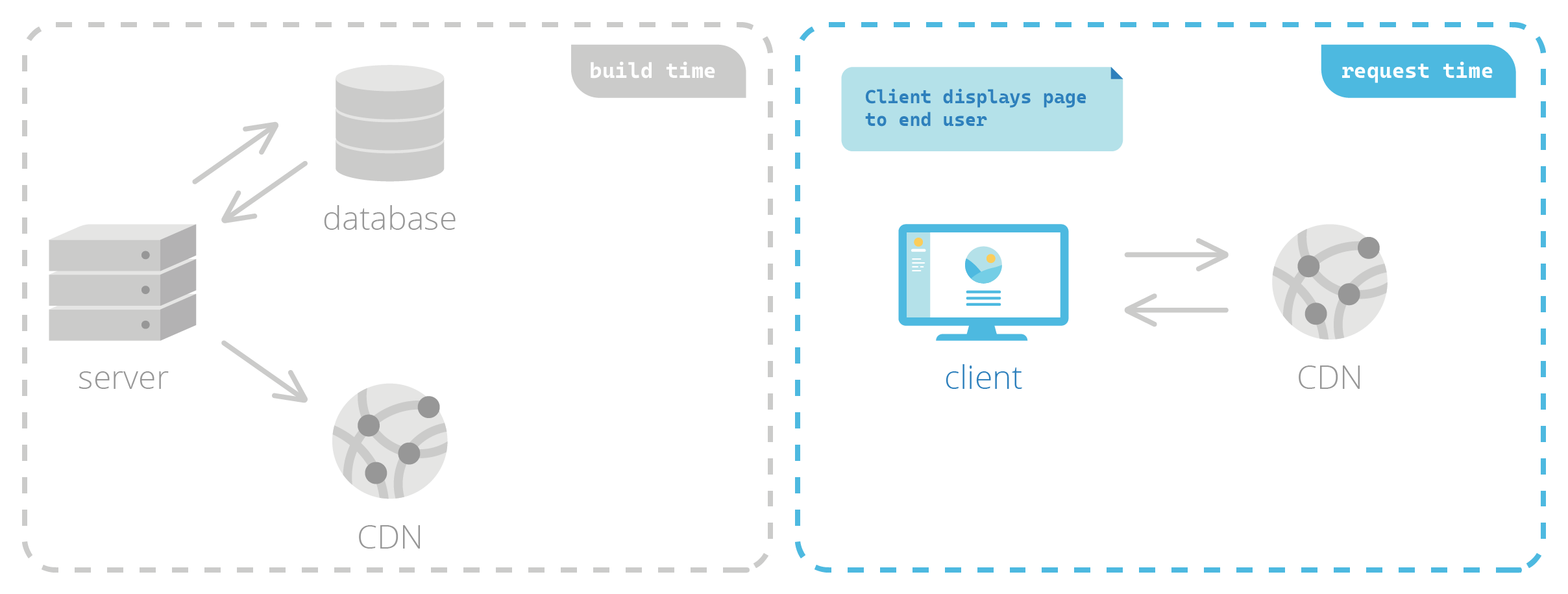
With statically generated sites, HTML pages are pre-built before a user ever requests them. At build time, a server is responsible for retrieving data and fully generating the HTML. This process is very similar to SSR; the key difference lies in when the server carries out this responsibility. With SSR, this happens at request time—but with SSG, the HTML is generated before it’s ever requested.
The pre-built HTML, along with other assets needed to correctly display the page such as images and videos, is then typically cached in a content delivery network (CDN), a geographically distributed group of servers that can very quickly deliver content from a location near the client at request time.
2.3 Comparison of SSR & SSG
Now that we have an idea of what each approach entails, we can ask: what types of web applications would be better served by each strategy?
2.3.1 Search Engine Optimization (SEO)
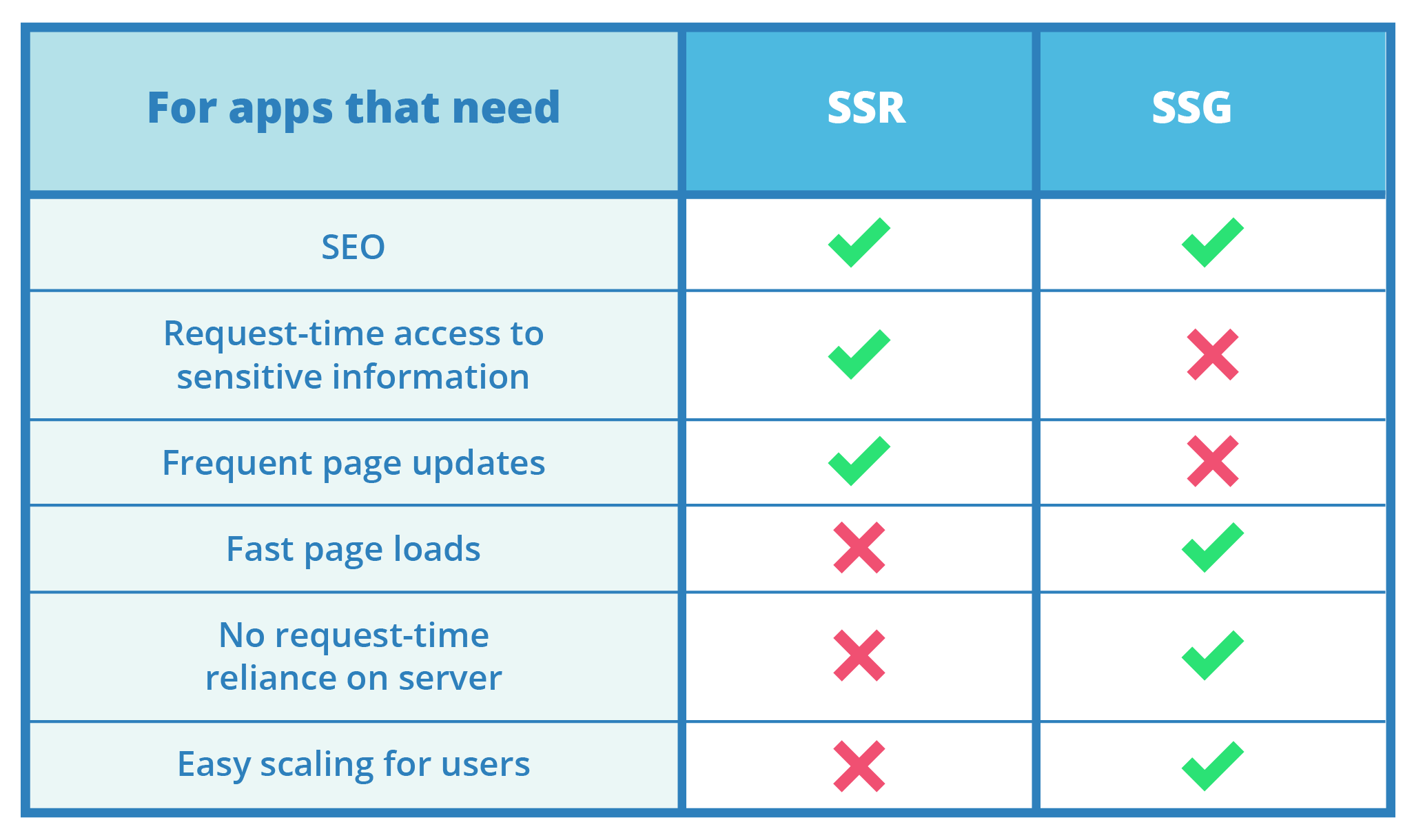
Both SSR and SSG are beneficial for apps that value Search Engine Optimization (SEO) since the HTML sent back to the client is already fully formed for web crawlers to parse and index.
2.3.2 Request-Time Access to Sensitive Information
Only SSR makes it possible to dynamically retrieve data at request time without needing to make a public API call using client-side JavaScript. This is necessary for apps that use secrets that shouldn’t be publicly accessible, for example, authentication information that may be needed to fetch data from a database and should only be known to the server.
However, SSG does offer its own security benefits in that with pre-built static files, there are fewer opportunities for attackers to inject malicious code or take advantage of potential server-side security holes. As a result, SSG is not suitable for displaying user authenticated content or processing user data. Although many features have been developed to overcome these limitations, SSG generally works best when the pages are consistent for all users.
2.3.3 Frequent Page Updates
SSR is a good fit for apps whose page content needs to remain up-to-date because the server regenerates the page on every single request. In contrast, SSG isn’t well-suited for such frequent changes since a build and deployment process must be executed each time a page’s content needs to be updated.
2.3.4 Page Load Speed
SSG is particularly useful for sites that require fast page loads. Statically generated sites excel in performance since all webpages are pre-built and served by a CDN without needing to run resource-intensive server-side scripts at request time.
With SSR, even though initial page loads are typically fast, there may be slower subsequent loading times.
2.3.5 Scaling for Users
Finally, SSG is a better fit for scaling for many users since CDNs by default can handle increased traffic at scale. An SSR architecture by nature does not necessarily have this same benefit.
2.3.6 Summary of Use Cases for SSR vs. SSG
Overall, web applications that can tolerate slightly longer page loads and whose pages need to remain up-to-date, access private data, and remain high in search engine rankings are well-suited to use SSR.
SSG, on the other hand, is well-suited for applications where fast load times are a primary concern and the content does not frequently change.
3. The Changing Landscape
3.1. Modern Web Development

Historically, applications could be neatly categorized into using either SSR or SSG. However, modern web development frameworks have begun to blur the lines between static and dynamic applications, ushering in greater flexibility by making use of a hybrid approach.3
Some examples of popular frameworks which support a hybrid approach, combining both server-side rendering and static site generation, are Next.js, Gatsby, and Vue.4
For applications that are content-rich but only require frequent dynamic data retrieval for select pages, it makes sense to use static site generation to pre-build simpler static pages in order to be able to serve those up quickly, while employing server-side rendering for pages requiring frequently changing, up-to-date content on demand.
A common real-world use case for this blended approach is with e-commerce applications.
3.2 Giraffe: A Target User
Let’s consider a hypothetical company named Giraffe as an example to better illustrate Bubble’s use case.

Giraffe is an e-commerce application that sells giraffe-related merchandise. They self-host an online storefront implemented with the Next.js framework.
Their application uses a mix of SSG and SSR to generate content: for example, the product categories page is generated through SSG, while product recommendation pages—which require data that’s unique to every user—are generated with SSR.
Giraffe chose Next.js for its many features that align with marketing optimization, such as image optimization for product discovery and built-in analytics for the performance of their site.
4. The Problem
Recently, Giraffe’s been doing very well. They’ve hired additional engineers to develop new features and bring a new look to their website, but they’re starting to experience bottlenecks during the development process.

Since multiple developers often work on new features simultaneously and also need to collaborate with various other departments, collecting feedback from different teams is starting to take too long and involves a lot of back-and-forth—even for very simple UI changes.
At this point, Giraffe is asking what they can do to streamline this process.
4.1 Getting Feedback in a Manual Way

Before the recent expansions in their organization and additions to their site, sharing progress was easier for developers at Giraffe.
They used manual approaches like sending screenshots to each other, or screen-sharing for interactive features.
Occasionally, when non-technical stakeholders from other teams wanted to look at the progress more closely, developers would take the time to help them pull down the code and run it on their local machine. However, with larger teams including remote colleagues and more non-technical stakeholders, it’s no longer practical to spend increasing amounts of developer time helping colleagues download and run local versions of the application to review changes.
4.2 Using a Shared Staging Environment
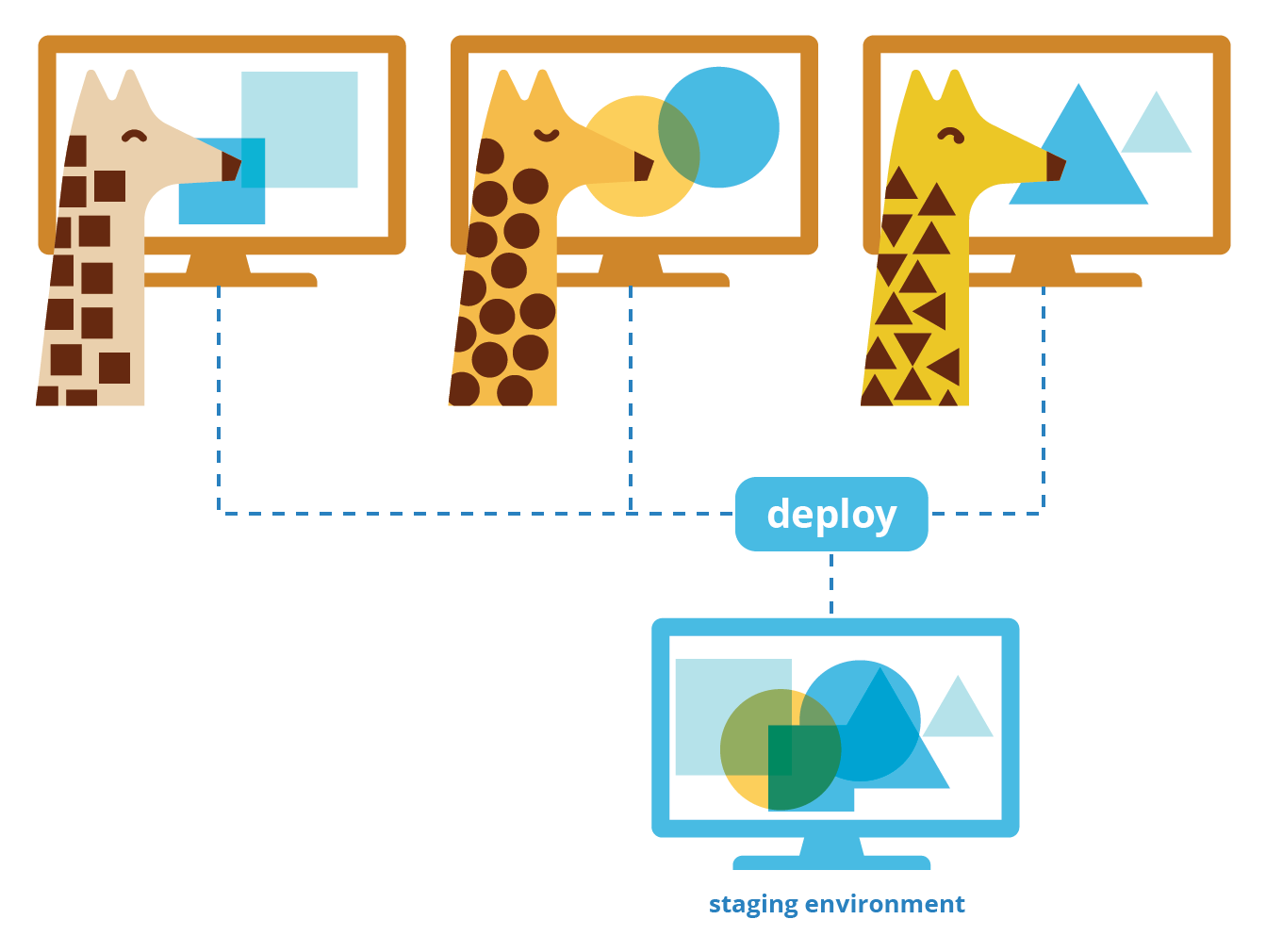
One tool that Giraffe uses as part of their development workflow is a shared staging environment. This is an environment shared amongst all developers collaborating on a repository.5
A shared staging environment aims to mimic the production environment as closely as possible to ensure all new changes are working as intended before they are released live.
Different types of testing can occur when code is pushed to this kind of environment: for example, load testing to simulate real-life traffic and determine a website’s performance under such conditions.
Using a shared staging environment gives non-technical stakeholders a way to examine changes without having to build and run the application themselves. This allows them to easily examine and provide feedback on in-development UI/UX features.
However, multiple teams making different changes to a single environment presented another set of challenges to Giraffe’s workflow.
4.3 Downsides to a Shared Staging Environment
4.3.1 Batching

Since there was only one staging environment for Giraffe to use, oftentimes newly-developed features would end up living together, intermingled within a single environment.
4.3.1.1 Bugs
Batching together multiple distinct changes in this way caused bugs to arise that were difficult to troubleshoot, because they could have stemmed from conflicts between any of the code updates pushed to the staging environment by different developers.
4.3.1.2 Bloated Releases
This type of workflow also led to less-frequent and more bloated releases: with only one centralized environment for non-technical stakeholders to use, reviews tended to happen in larger batches. And when something went wrong and a release needed to be rolled back, it was much more challenging since the releases weren’t atomic.
4.3.2 Queuing

In an attempt to resolve these issues, Giraffe has switched to queuing instead, allowing only one development team at a time to use the staging environment. This has taken care of the bugs, conflicts, and bloated releases that occurred when distinct changes were all batched together, but has introduced a different set of challenges to their development workflow.
4.3.2.1 Wait Time & Premature Deployment
With only one team allowed to use the shared environment at a time, developers now have to wait for the environment to be freed up before they can use it. One side effect of queuing is a higher risk of deploying unsafe code, which can happen when a developer mistakenly rushes to deploy another colleague’s work in an attempt to free up the staging environment for their own use.
4.3.2.2 Long Feedback Loop
Another consequence of queuing has been that valuable developer time is wasted: the feedback loops formed by developers and reviewers are now much longer than before since features often need multiple rounds of changes before they can be moved out of the shared staging environment. Only then can next-in-line changes be reviewed.
5. Preview Apps
Because of the challenges associated with using their shared staging environment to iterate on UI/UX changes, Giraffe is looking for other options that could allow them to shorten their feedback loop and minimize bugs from conflicting updates.
5.1 What Are Preview Apps?
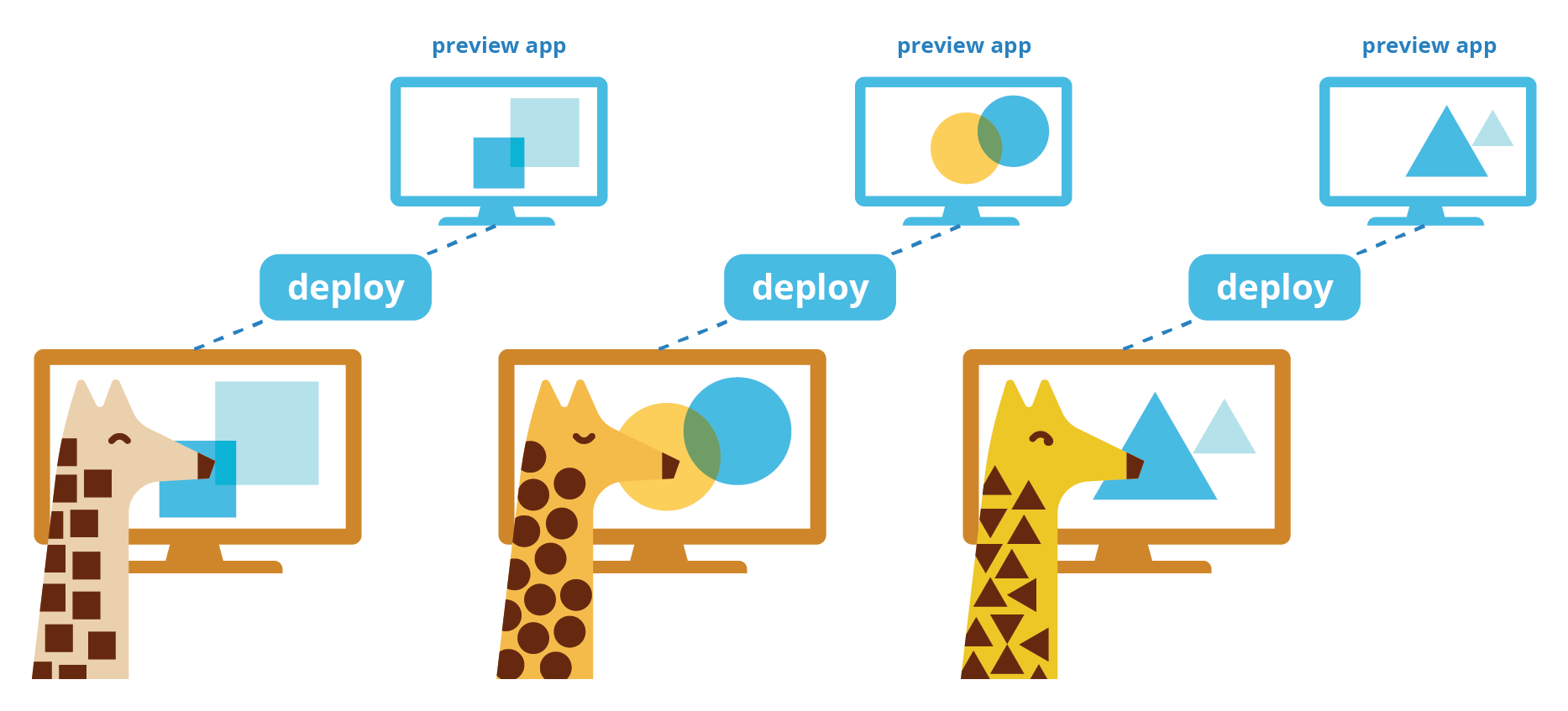
Preview apps are one way to allow non-technical stakeholders to quickly review UI/UX changes.6 Preview apps are ephemeral, lightweight, and fully functional versions of an application that can be easily built and deployed—and just as easily torn down. They allow multiple versions of a site to be quickly deployed in isolation: this way, non-technical stakeholders can more easily give feedback on UI/UX changes, and developers can more quickly iterate after receiving that feedback.7
Each time they wanted to show a new change, a Giraffe developer could deploy a new preview app and share its URL with all relevant stakeholders for evaluation.


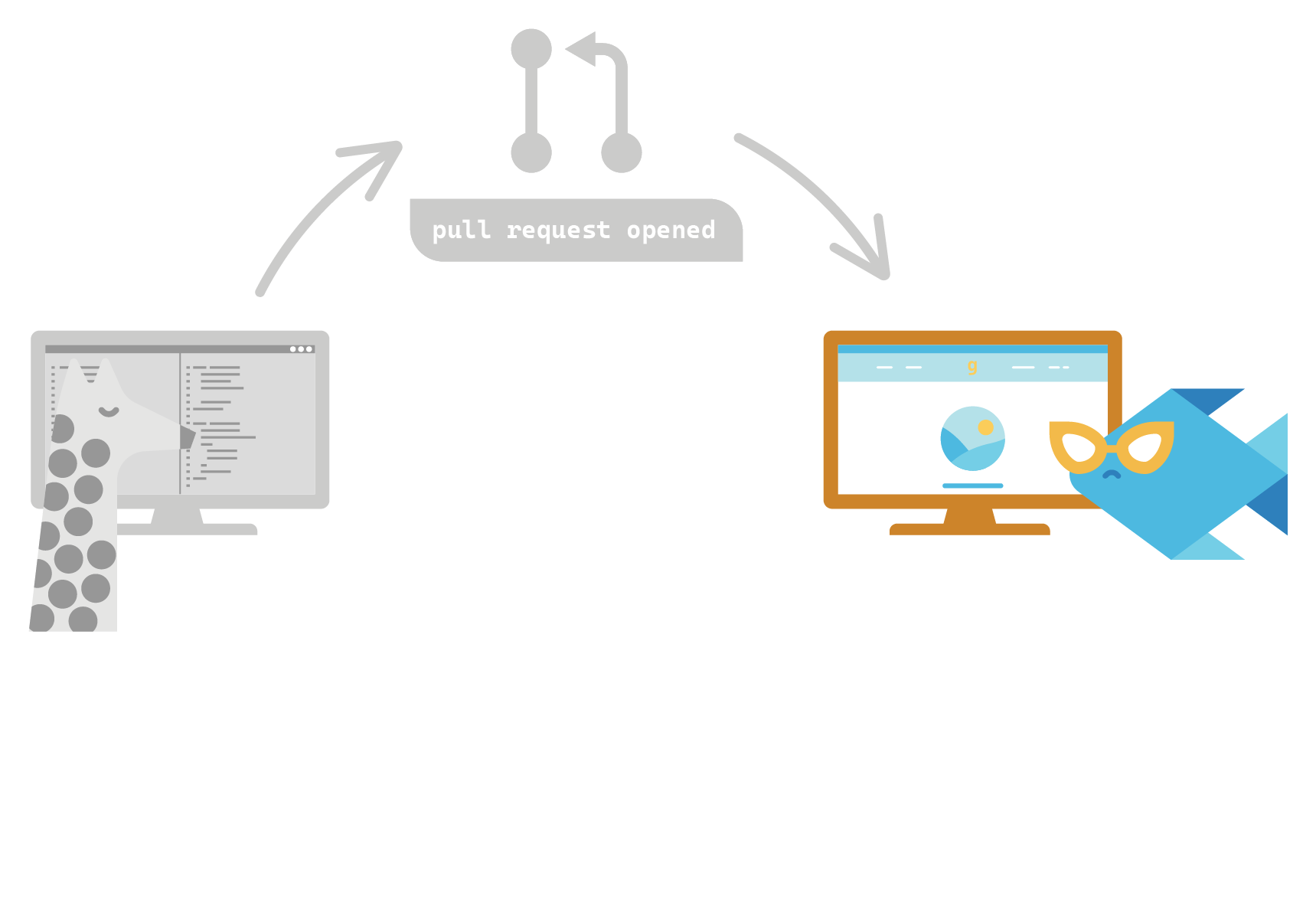







The development workflow using preview apps would be carried out as follows:
- When a developer is ready to share their new feature, they initiate a pull request for their feature branch.
- A preview app is automatically built and deployed with the new feature code, and a unique URL is generated to access it. Product managers and non-technical teams interested in the feature use this URL for reviewing the changes.
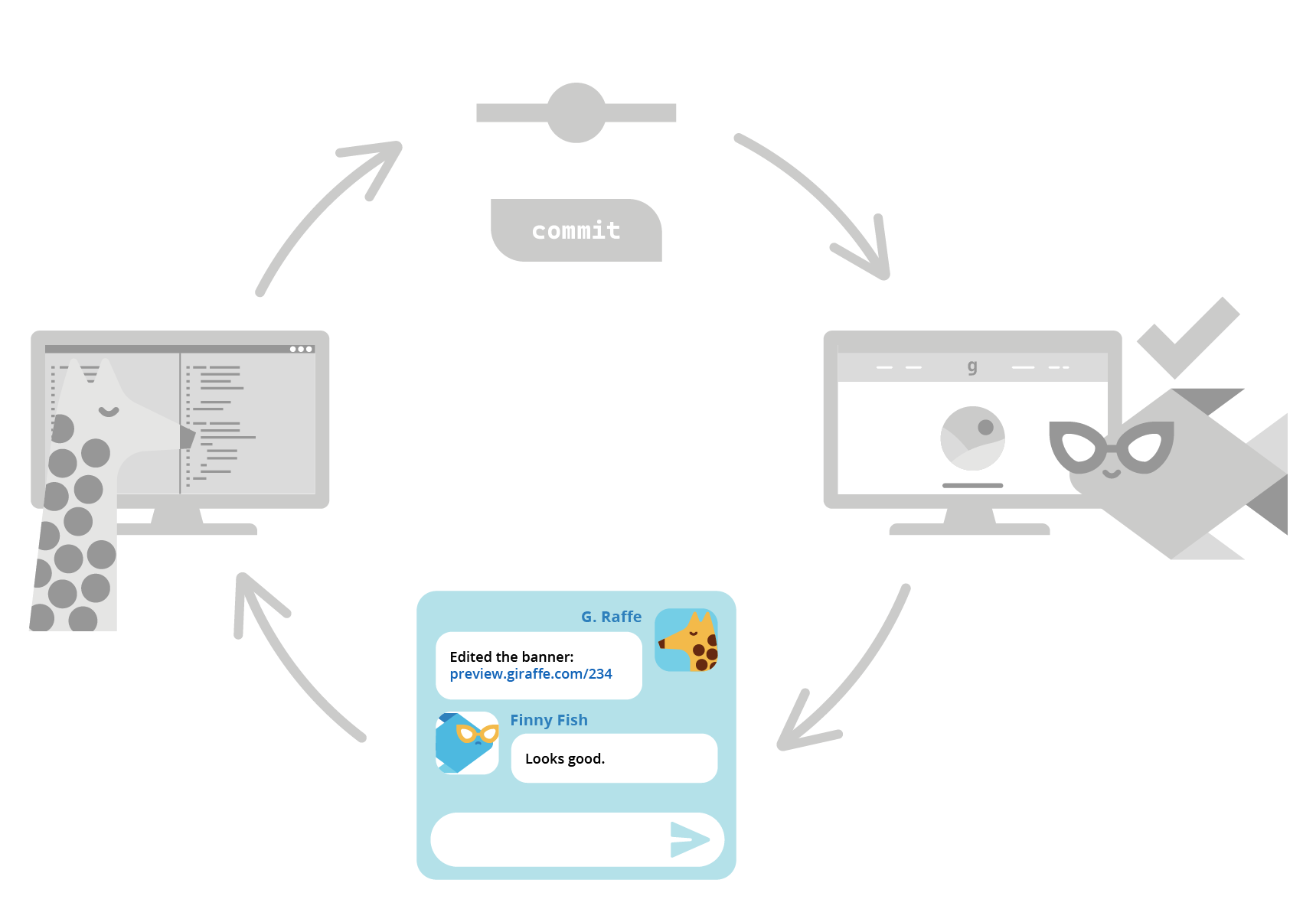
- The developer makes any necessary changes based on feedback and commits to the same feature branch.
- A new preview app is deployed with the changes with a distinct URL. Since each iteration on the feature branch has its own separate preview app and URL, they can easily be compared side-by-side.
- The feedback/preview app cycle continues until all stakeholders are happy with the new feature, at which point the code can proceed to the next step in the development pipeline.
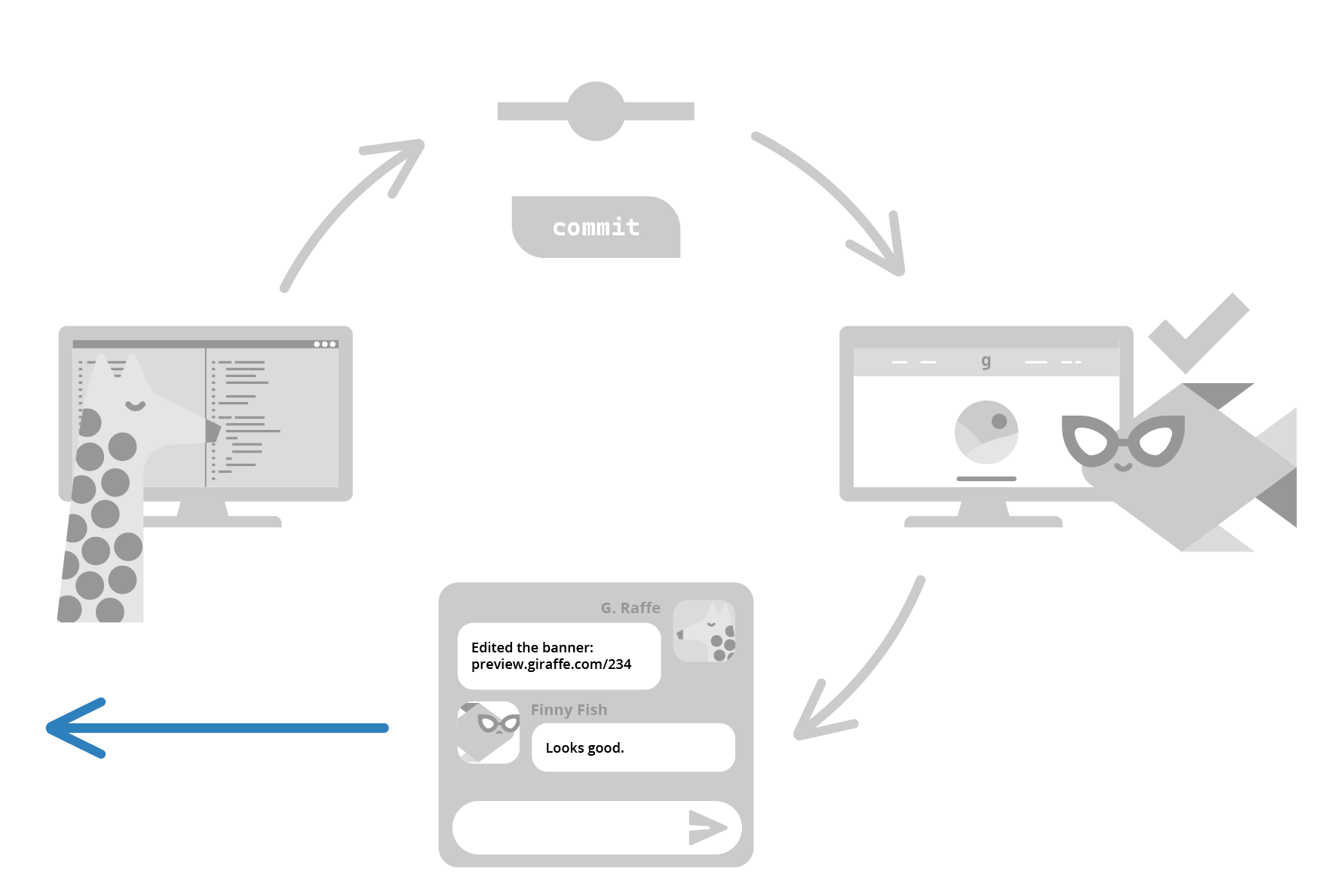
- Once the developer merges and closes the pull request, any associated preview apps are automatically torn down.
5.2 Benefits of Preview Apps

Preview apps reduce some of the headaches that occur when stakeholders use a shared staging environment to review and discuss UI/UX changes.
Each new feature can be reviewed in isolation from other application changes still under development, eliminating the chances for hard-to-track-down bugs that may crop up from code conflicts with other new features.
In addition, since each developer can deploy and share a preview app for each new feature as frequently as they’d like, they can receive feedback from all stakeholders faster, leading to a more efficient development process with a shortened feedback loop.
5.3 Downsides of Preview Apps
While preview apps help to streamline the process of developing frontend features, they're not the right choice for everyone.
Since they’re intended for testing new features in isolation, preview apps are not a good fit for testing how multiple changes integrate with one another. They also incur costs, as additional infrastructure is provisioned for each preview deployment. And since each preview app has its own URL, interested parties need to manage multiple links, which could become unwieldy as more previews are deployed.

There are some additional drawbacks depending on whether a team chooses a third-party preview app service or decides to DIY their own. The former racks up more costs in the form of usage fees and requires that code and data are shared externally with the preview app provider, which may be a concern for some organizations.
The DIY solution, on the other hand, adds labor and opportunity costs in the form of development time.
After weighing the pros and cons, Giraffe has decided to move forward with integrating the use of preview apps into their development process. Now they need to consider the specific type of preview app solution they will need.
5.4 What Are Dynamic Frontend Preview Apps?
As the landscape of web development has changed and the lines between SSR and SSG have become blurred, the requirements for preview apps have grown.

For applications using only SSG, all that a preview app would need is a CDN to deliver static assets; for only SSR, that preview app would only require a server. However, to support applications utilizing both SSR and SSG, the preview app architecture must include both an application server and a CDN, and this adds significant complexity to the design.
To support their hybrid application, Giraffe will thus need to find a preview app provider that can handle this complexity to allow them to benefit from fully functional preview apps.
6. Existing Solutions
There are several existing solutions for preview apps that present different benefits and drawbacks for a company like Giraffe.
6.1 DIY

One option would be a DIY approach.
Building their own system would allow Giraffe to customize their solution according to their exact needs while maintaining full control of their code and preview app infrastructure. The downside is that it’s a time-consuming and complex task to make all the necessary decisions and build out all the components necessary to implement fully-functional preview apps.
To construct their DIY solution, Giraffe would need to examine multiple sets of tradeoffs to decide where and how to build and deploy their preview apps. With their design decisions made, they would then need to implement their system, which would include configuring, building, and deploying static assets, routing, and business logic—as well as writing code to automate this entire process and integrate it into their development workflow.
Given the time and resources it would take to implement their own system, Giraffe may prefer to look at already-made options.
6.2 Feature vs. Service

Preview app solutions on the market typically fall into two categories: feature and service. Both can offer a variety of features and provide dynamic frontend preview apps that support any combination of implementations using SSR and SSG.
6.2.1 Preview Apps as a Feature
The first category, preview apps as a feature, refers to preview app functionality that is included as part of a hosting platform. Preview apps as a feature are generally easy to set up and use, and offer an abundance of functionality; however, they require a company’s code and data to be hosted and deployed using that provider’s infrastructure.
If a company is already using a platform like Vercel or Netlify, it would be simple for them to leverage the preview app features they already have access to, but changing hosting providers is a large and complex undertaking. It typically wouldn’t make sense to do so for the sole purpose of using preview apps.
6.2.2 Preview Apps as a Service
The other category is preview apps as a service: these are standalone options that can be used on their own without changing hosting platforms. As a separate service, these options take more setup time and configuration, often requiring the user to write custom files before preview apps can be built and deployed. Preview apps offered as a service are also typically subscription-based, requiring payment for the service regardless of how much or how little it is being used.
*Out of all the currently available preview apps solutions, only one, GitLab, is open-source, and it provides preview apps as a feature, meaning it requires that code be hosted on its platform to access its preview apps functionality.
7. Introducing Bubble
7.1 Where Bubble Fits In
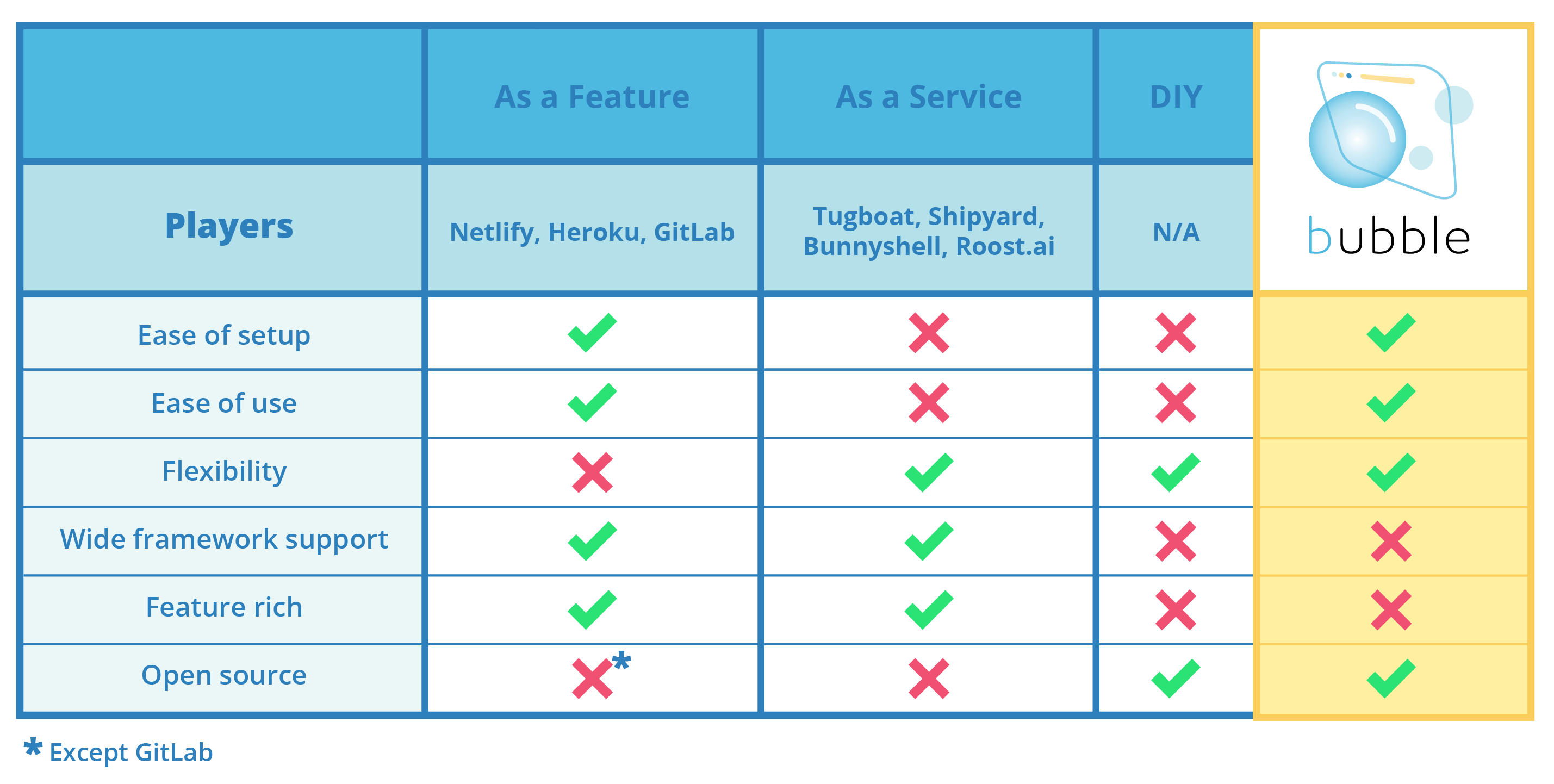
Bubble combines some of the benefits of both preview apps as a feature and a DIY approach at the cost of supporting fewer features.
The benefits of using Bubble are that a company like Giraffe can have preview app functionality that’s easy to set up and use—like preview apps as a feature—while maintaining complete control of their code and data—like a DIY approach.
The tradeoff is that Bubble won’t be completely customized in the same way a made-from-scratch solution would be, nor does it support the range of languages and frameworks that a hosting platform would.
7.2 Feature Overview
Bubble has a few important features:
- It automatically deploys preview apps when a pull request is opened as well as when subsequent commits are made to the branch associated with the pull request. Each deployment generates a shareable URL that will be posted on GitHub as a pull request comment.
- When the branch is merged or the pull request is closed, all associated preview apps will automatically be torn down.
Bubble provides two user interfaces:
-
a visual dashboard where the user can manage preview apps across all their local repositories
-
a command line interface (CLI) where the user can interact with the preview apps for one repository at a time
8. Using Bubble
Let's take a further look at the two user interfaces that Bubble provides: the CLI and the dashboard.
8.1 Prerequisites & Installing Bubble
Getting started with Bubble requires the following prerequisites:
- A Next.js project repository
- An AWS Account and AWS CLI configured for the account
- A GitHub Token with repository-level permissions
- Node.js and
npm
Users can install Bubble by running the following npm command:
npm i -g jjam-bubble
8.2 The Bubble CLI
After installing Bubble, the following commands are available on the command line:

8.3 The Bubble Dashboard

Users can access the Bubble dashboard using the command bubble dashboard from a Bubble-integrated local repository.
Once the dashboard is open, all preview apps on all branches in that repository with open pull requests will be displayed. Users are shown links to each preview app, as well as to the GitHub workflow run for that preview app deployment, where the build logs are available.
From this view, the user is also able to click the Destroy button, which will begin the destruction process for all preview apps belonging to that repository.
Users may navigate to other Bubble-integrated repositories by using the sidebar or the homepage.
8.4 Adding Bubble to a Project

If the user has a Next.js project to which they would like to add Bubble, the first step is to run the bubble init command in their repository’s root directory.
Bubble will then request a GitHub Personal Access Token (if this isn’t the user’s first time using Bubble, they may continue to use the same token for subsequent Bubble-integrated projects).
A .bubble folder will be created in the user’s local machine’s home directory to house their configuration details, data on all active Bubble-integrated repositories, and all code and packages needed to successfully run the dashboard. Another folder, .github/workflows, will be created in the project directory. The contents of this folder are the GitHub Actions workflow files necessary for automating preview app deployment and destruction.
Afterward, Bubble provisions a new AWS IAM user and configures the user under a new AWS command line profile. Any AWS commands executed from the repository will run under that profile, so that Bubble only has access to resources related to the current repository’s deployments. The user’s AWS access information and GitHub token will be encrypted and saved to GitHub secrets.
Lastly, to keep track of preview app metadata for the repository, a new DynamoDB table will be spun up with the newly created AWS IAM user credentials.
9. Bubble Architecture
In the previous section, we saw how Bubble works from a user perspective in regards to the user interface, and got a glimpse a few of the GitHub and AWS pieces involved when integrating Bubble into a repository. Let's now take a closer look at where each of these components fits into Bubble's overall architecture.
9.1 Architecture Overview

Bubble consists of three main pieces of architecture: a local user interface, GitHub, and AWS.
9.1.1 Interfaces

As we've seen, the user interface consists of two parts located on the user’s local machine.
Once Bubble is globally installed as an npm package, the user can then access the CLI to initialize an instance of Bubble in a repository directory. This adds necessary files to the local repo and updates files for the dashboard to use.
The dashboard is a locally-run web application that provides a user-friendly visual interface for viewing, managing, and destroying preview apps. It combines a back-end, which makes API calls to AWS, with a front-end for the user to view in their browser.
9.1.2 GitHub Actions

Bubble uses GitHub Actions to automate the build, deploy, and destroy process for preview apps. These actions execute workflow files added by Bubble which are triggered through initial pull requests, subsequent commits to those requests, or HTTP requests to GitHub servers sent via the Bubble CLI.
GitHub Actions run on their own servers, so GitHub takes care of spinning them up and down and executing the workflow code.
9.1.3 AWS Services

The final piece of our architecture uses several AWS services to deploy the infrastructure for all preview apps.
Each preview app consists of three AWS microservices:
- SSR logic and API routes are deployed to Lambda@Edge functions.
- S3 Buckets store static assets such as images and pre-built files.
- CloudFront serves both static and dynamic content by associating the functions and S3 buckets to each route of each preview app.
Permissions management and preview app metadata storage are handled by two additional services:
- All AWS commands executed by Bubble are carried out through IAM users endowed only with the permissions they need to create, manage and destroy Bubble preview apps. This allows for separation of access from other resources on the user’s AWS account.
- Two DynamoDB tables are provisioned to hold metadata related to users’ preview apps.
10. The Build Process: Where to Build?
The first major design decision we tackled was where the build process should take place.
Bubble automatically builds preview apps on two triggers. One is the opening of a new pull request and the other is any subsequent commit to a branch with an open pull request. Since these events occur within the context of a GitHub repository, we had to decide where we would be able to execute the build process as an automated response to these events.
10.1 GitHub Actions
10.1.1 What Is GitHub Actions?
GitHub Actions is an automation tool that allows users to execute code written in repository files called "workflows" using GitHub Runners, which are temporary virtual servers that GitHub spins up and down.8

The process—using a Bubble deployment as an example—works as follows:
- A Bubble workflow file in the user’s repository is set to listen for pull requests.
- When a pull request is opened, the workflow is triggered and GitHub automatically spins up a runner to execute the workflow.
- Based on the contents of the workflow file, the GitHub Runner builds and deploys a preview app.
- After the workflow file finishes execution, the GitHub Runner is automatically spun down.
Instead of having to provision and configure our own build server to run each build process—which would add unnecessary complexity and setup work to our architecture—GitHub Actions provides a simpler way to integrate with GitHub and carry out the build process directly within the context of a repository.
10.1.2 Benefits & Drawbacks of Github Actions
As with most engineering decisions, there are tradeoffs associated with using GitHub Actions.
One challenge with using GitHub Runners is that they are entirely managed by GitHub and thus cannot be accessed directly, making it difficult to extract outputs and other environmental artifacts. In addition, development is much more constrained than it would be if we were configuring our own build server since workflows can only be defined with YAML files.
However, the benefits of using GitHub Actions ultimately outweighed these drawbacks when it came to Bubble’s needs. GitHub Actions includes a free tier that we estimate provides enough compute to make building and deploying preview apps very inexpensive, if not free, for a typical mid-sized team using Bubble.
Relying on GitHub Runners is also much simpler than implementing and configuring a custom build server and thus abstracts complexity away from our architecture.
Finally, since each section of a workflow file can be run on a separate GitHub Runner, GitHub Actions allows Bubble to deploy and tear down preview apps in parallel, making this process more efficient.
11. The Build Process: How to Build?
11.1 The Application Server

Recall that the essential architectural component differentiating a static frontend application from a more complex dynamic one is the need for an application server to generate SSR pages at request time.
Since Bubble aims to let users share new UI/UX features quickly and conveniently, we considered options that would allow us to build and deploy applications that include application servers in a lightweight and cost-efficient manner.
11.1.1 Containers
One option would be to deploy the server-side logic and static assets together in a container.
A container encapsulates the application code along with all the runtime elements necessary to execute it together in one package.9

With containers, we wouldn’t need to set up and configure multiple nodes of infrastructure or implement routing logic to connect them; instead, we’d be able to deploy only one single entity for each preview app, as the entire application would be spun up in the container as a whole. Since there’s only one piece to consider, containers can easily be moved around and deployed.

However, containers are constantly running, and would therefore incur costs even while the application is not in use. They also have longer build times since the virtualized OS and runtime need to be built and packaged together on top of the preview app itself.
11.1.2 Serverless Computing
An alternative to containers would be deploying the server-side logic and static assets to separate services. Given our use case of providing temporary preview apps, we found serverless functions to be the most compelling option for deploying server-side logic.
Despite being called serverless, these functions do run on servers, but they abstract away the logistics of provisioning server resources.10 They have no ongoing expenses: developers are only charged for the server capacity that their application uses during the time it’s being executed.
Since they don’t need to include system dependencies, serverless functions are also very fast to deploy, typically going live within milliseconds.
One downside of serverless functions is the added complexity of the architecture for preview apps: as opposed to containers, using serverless functions requires multiple nodes of infrastructure as well as routing logic to direct traffic between them.
Another inherent drawback is what’s called “cold starts”: since serverless functions aren’t constantly running, they have to be spun up before beginning execution. This can sometimes take several seconds, which can lead to longer loading times for SSR pages.
Ultimately, we chose to use serverless functions rather than containers. Bubble’s preview apps do not need to be highly performant, so cold starts are acceptable. In terms of the architectural complexity, although serverless functions necessitate additional infrastructure, being able to use separate services for SSR and SSG allows us to fully optimize for a hybrid approach which combines them.
As we delved further into utilizing serverless functions for our preview apps, we considered three open-source frameworks with which to automate deployment.
11.2 Serverless Computing Options
11.2.1 Terraform

Terraform is the first tool we considered.
Terraform is an “infrastructure as code” framework used to manage the lifecycle of cloud components.11 There are many existing modules of Terraform for deploying frontend applications that are free to utilize and actively maintained.
Compared to other solutions, one of the most promising modules we found uses a more complex architecture to deploy apps. The AWS services used include CloudFront to handle incoming traffic, a Lambda@Edge function that acts as a proxy handler to route requests, an S3 bucket for static content storage, Lambda functions for serving the dynamic SSR pages, and an API Gateway that balances traffic between the Lambda functions.
The cost of this heavy underlying infrastructure is lengthy deployment times. During our test runs using this module with multiple applications, we found that deploying a simple app took more than 15 minutes. We also encountered a few deployment failures, which were challenging to debug because of this complexity and ultimately led us to question the reliability of this option.
11.2.2 FAB

Frontend Application Bundle (also called FAB) is another open-source framework that enables users to deploy frontend applications through a CLI.12
FAB zips up entire applications and ships static assets and server-side logic separately. Thus, the user has the option to choose separate platforms for serving static and dynamic content. For example, they could deploy static assets to AWS S3 while deploying serverless functions with Cloudflare workers. Although it aims to be platform agnostic, for serverless functions, FAB is currently most streamlined for Cloudflare Workers and AWS Lambdas.
When using FAB to deploy a few applications, it took no more than 5 minutes to deploy each app, which was significantly faster than other tools we considered, especially Terraform.
However, unlike the other options, FAB has not been maintained for over a year and a half.
11.2.3 Serverless Framework

The final option we considered was Serverless Framework.13
Serverless Framework deploys apps using only three AWS services: CloudFront, Lambda@Edge, and S3. This is a simpler architecture in comparison to the Terraform module, which may be a contributing factor to its faster deployment time. While provisioning the CloudFront distribution does take a few minutes, it still took less than half the time to deploy compared to Terraform.
One downside of using Serverless Framework is that unlike the flexibility of FAB, it currently only supports deployment on AWS infrastructure. Moreover, server-side logic can only be deployed to Lambda@Edge functions. However, while FAB is no longer maintained, Serverless Framework has continued to be a reliable framework considering how many people use it. Its contributors are still active and its latest version was released just a few months ago in March 2022.
In the end, we decided to go with Serverless Framework to build and deploy Bubble’s preview apps, due to its reliability, relatively fast deployment time, and simplified architecture, which would best serve Bubble’s goal of automating lightweight and convenient preview apps.
12. Additional AWS Services
12.1 IAM

Bubble creates new IAM users for identity and access management. An IAM user for a particular GitHub repository will have limited access to only those resources needed for Bubble’s features. The access key for the user is saved locally on the user's computer and also in GitHub secrets. This maintains a separation of access to resources on a user’s AWS account for other use, limiting the damage that a malicious user could do if they were to act on the IAM user’s behalf.
12.2 DynamoDB

Bubble persists metadata in order to keep track of all the preview apps and their resources including CloudFront distributions, S3 buckets, and associated Lambda functions. Because Bubble automatically destroys preview apps on pull request triggers through workflow files, the data needs to be accessed remotely from a GitHub Runner.
One option would have been to save the data locally on the user's computer and spin up a server listening for API calls from GitHub. However, that would necessitate a long-running server provisioned either on the user's local machine or through a cloud provider on their behalf.
Instead, Bubble provisions DynamoDB tables during initialization and saves metadata to them whenever a preview app is deployed. Because the IAM user’s access key is saved in GitHub secrets, workflow files can access those keys to configure the AWS command line tool on the GitHub server.
Furthermore, DynamoDB tables are provisioned in an on-demand capacity mode, which furthers our goal of being lightweight and low-cost. This means the user is only charged for data writes and reads. These tables are torn down automatically if the user ever executes Bubble’s resource destruction command from the Bubble CLI.
13. Challenges
Now that we’ve explored how Bubble works and some of the design decisions we made, let’s dive further into two of the challenges we encountered during implementation.
13.1 Lambda Function Deletion

One challenge occurred when we were deleting preview apps.
For building and deploying preview apps, we used GitHub Actions to run workflows, and we decided to use this same mechanism for tearing them down. These workflows can be triggered automatically, by the closing of a pull request, or manually, using the bubble destroy command through the CLI.
When the workflow to destroy a preview app is executed, all AWS resources provisioned for that preview app should be torn down. These resources include the S3 Bucket storage, CloudFront distribution, and Lambda@Edge functions. AWS associates Lambdas with a CloudFront distribution, so the order in which we delete each resource is important.
In our Bubble Destroy implementation, we first request that AWS remove the S3 bucket storage, then the CloudFront distribution, and finally the Lambdas. However, even when the CloudFront distributions are successfully deleted, an error often occurs when we attempt to delete the Lambdas. The error states that additional time is needed before they can be deleted—this amount of time can range anywhere from a few hours to a day.
Upon further research, we learned this is an AWS limitation when working with Lambda@Edge functions, so we had to find a way to work around this issue.
13.1.1 Polling

One solution we considered was polling: repeatedly trying to delete the lambdas and checking whether or not the attempt was successful. This would have involved setting up a process often referred to as a cron job, which enables developers to automatically and repeatedly execute scripts at specified times.
Had we chosen this approach, Bubble would have set up a cron job to execute in the background after the user executed bubble destroy: this cron job would have attempted to delete the Lambdas at a specified time every day until none remained.
The downside to this approach is that cron jobs run on the operating system: accordingly, configurations would have differed across operating systems. Multiple implementations would have had to be developed for different systems, all of them including the cron job itself as well as the manual setup of logging in case of errors, the monitoring of those logs, and the additional logic needed to restart the job if the computer were rebooted.
Rather than relying on the user’s local machine, another possibility would be implementing a cron job on AWS; however, this would increase costs for the user and add another resource for the application to manage.
As a result, we decided that cron jobs would not be a good fit for this specific task.
13.1.2 Additional CLI Command

Instead of cron jobs, we decided to add a command named bubble teardown which users can run themselves later after running bubble destroy to remove any remaining Lambda@Edge functions.
To make this change, we had to adjust how we maintained the information necessary to tell AWS to remove these functions. We decided to add another table to the DynamoDB database to store metadata for each Lambda. This meant that we also had to alter the workflow for building and deploying preview apps so that the Lambda metadata would be saved during each deployment.
This new table is now used when the user runs bubble teardown so that Bubble can identify which functions to delete when issuing AWS CLI commands; once all functions are successfully deleted, the table is then removed.
Modifying our build workflow and adding this additional table slightly increased the complexity of our application, but we felt it was simpler than implementing multiple cron jobs and the logic it would take to monitor and eventually remove them from the user's system or AWS.
13.2 Build Logs
Another challenge we experienced involved capturing the preview app build logs and integrating them into our dashboard.
Inspecting build logs can be very beneficial for technical stakeholders because it allows them to examine how their code is being built and deployed, and to be able to investigate in case of failure. Therefore, we wanted to display them on the dashboard interface.
Our initial plan was to capture and parse the logs so that we could include them in full on the dashboard. That way, when a user selected a particular preview app deployment, they would be able to view the logs immediately. This turned out to be surprisingly difficult to implement.
13.2.1 Accessing the Logs
As previously discussed, we used Github Actions to deploy and build preview apps. One downside of GitHub Actions is how opaque the runtime environment is.
GitHub Actions run on temporary virtual servers which are spun up when a workflow is executed and spun down as soon as execution is complete; this means that the environment for each build is transitory. Therefore, we had to find a way to begin the process of capturing the logs live rather than after the fact.

Our first attempts to capture the logs during the build process were unsuccessful because the Action run logs are only available via an API call after the entire execution has finished.

We ended up having to cache the run_id for each workflow on GitHub and then implement an entirely separate workflow which was triggered immediately after each build action finished. This allowed us to access the build logs in their entirety within the new workflow.
13.2.2 Parsing the Logs

The next hurdle after retrieving the logs was cleaning and parsing them.
As part of displaying workflow execution logs on their site, GitHub injects a variety of metadata and special character sequences. These sequences are used by GitHub when streaming the logs on the GitHub Actions console on their site, but they lead to numerous string parsing errors when handled within a workflow on a GitHub Runner.
Trying to parse these logs was a painstaking process of manually going through thousands of lines of logs and attempting to eliminate these inserted characters without removing meaningful log data. The number of edge cases that required special handling kept growing and growing with no end in sight.
13.2.3 Storing the Logs
In addition to the snowballing parsing challenges, we also had to decide how and where we would store the logs. Build logs can easily contain thousands of lines, so they are not trivial to store.
Since we were already utilizing AWS microservices for our architecture, we limited our options to their offerings. We began by considering DynamoDB, which we were already using in each Bubble project. However, we realized that a set of logs could easily exceed the single-item storage limit.
Another option we thought about was using additional S3 buckets to store the logs as objects. After the initial parsing, there would be no need to ever update the logs; we could simply retrieve them later, in one piece, as they were originally stored. This means that object storage would be a good fit for the logs.
Although we’d found a suitable way to store the logs, another major concern that grew increasingly apparent was the potential impact of cost for the user: as the logs stored piled up, additional AWS charges would accrue for our end users.

As we progressed further down this route and realized both our development and architectural complexity were increasing notably, we chose to streamline this feature and move in a different direction.
13.2.4 Solution: Link to Logs
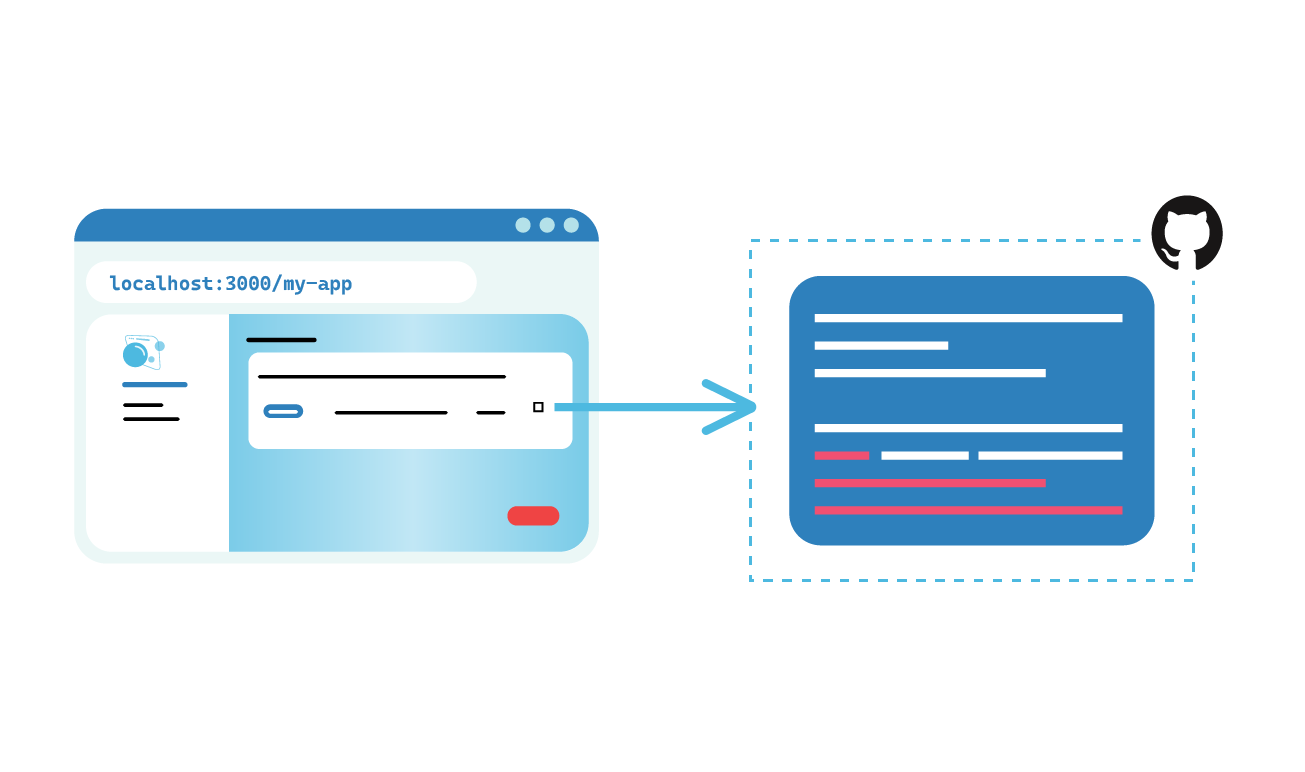
Instead of processing the logs ourselves and making them available in full on the Bubble dashboard, we decided to add a link on the dashboard for each preview app’s build log. When followed, this link takes the user directly to the GitHub workflow run where they have the option to download the logs for that specific preview app.
Although this option requires a couple more clicks for the user, it significantly reduces the complexity of Bubble itself as well as the storage needs and costs of the user’s AWS account.
14. Future Work

Now that we’re well-acquainted with Bubble and the design decisions that went into building it, the following are some features we’d like to include in the future.
14.1 Support Additional Frameworks
Currently, Bubble only supports the Next.js framework. We would eventually like to support building and deploying preview apps for other frontend frameworks such as React and Vue.
14.2 Share the Dashboard
At the moment, the dashboard can only be viewed by the developer who installed Bubble. In the future, we would like the dashboard to be distributed so that developers from the same team can share one dashboard to manage and view their preview apps in one place.
14.3 Deploy to Other Cloud Providers
Finally, Bubble’s preview apps are currently only deployed on AWS infrastructure, and we’d be interested in exploring how to integrate our solution with alternative cloud providers, such as Cloudflare and Google Cloud.
15. References
- A Brief History of the Web
- What are Static Site Generators?
- SSG History: SPAs are awesome
- SSR vs CSR vs SSG
- Staging Environments are Overlooked: Here's Why They Matter
- With Preview Environments, Everyone is Invited to the Party
- FeaturePeek — Front-end review for the whole team
- GitHub Actions Overview
- Containers
- What are Serverless Functions?
- Terraform
- FAB
- Serverless Framework
The Bubble Team



